From fragmentation to integration
Institute-wide research data management in structural engineering
Author: Dr. Julian Unglaub is Senior Researcher at the Technische Universität Braunschweig, Institute of Steel Structures. Currently, he leads a research group focusing on material and component behavior. In addition, he serves as the spokesperson for the “Damage Detection on Bridges” research cluster within the priority program SPP 100+ and is a reviewer for various scientific journals.
Keywords: research data management, object-oriented processes, clean code, quality assurance, long-term data usability

Fig. 1: ARS Prototype Screens, ARS Project, 2023 CC by 4.0
Introduction
Research Data Management (RDM) is crucial for preserving and accessing research data, preventing loss, and ensuring long-term usability. In today’s contemporary landscape of data-driven research and innovation, the FAIR principles, representing Findable, Accessible, Interoperable, and Reusable data, have become increasingly significant, particularly within the realm of engineering sciences.1 These principles serve as a solid framework for best practices, emphasizing the crucial role of data management in engineering research and applications. Due to the commitment of major funding agencies like DFG,2 and universities to research data management, there is a need for action also on the institute level.
Research data are primarily: measurement data, observations, simulation data, images and videos. These data are collected according to methodical procedures and by means of standardized procedures, questionnaires and checklists. The processing and analysis is done with software, which in turn can be seen as research data. This heterogeneity and reclusivity of the various datasets leads to a great deal of complexity. Software and standardization play a critical role in achieving this goal. There are many examples and studies showing the application and benefits of cooperative software systems for data management in collaborative projects.3,4,5 Although all examples follow the same principles, the design and implementation are very different. This is partly due to the different cultures of the disciplines or the composition of the consortium, but even within the same disciplines, implementation can be very different (GRK2075 vs TRR277). However, RDM is often implemented on a project basis, resulting in fragmented knowledge and no comprehensive overview of accumulated data and design.6
In the field of structural engineering, institutes generate large amounts of data during acquisition and evaluation, but often lack in-depth review, testing, and quality assurance. This leads to missing information and renders the data useless. Similar challenges exist in research source code, with limited clean code practices and systematic testing. Moreover, acquired data is often exported to various RDM regulations in individual post-processes.7
Researchers often create software to test their scientific hypotheses and validate their models. However, many of them lack formal programming or software engineering backgrounds, and their software development is often rushed for quick results and short-term goals due to time constraints.8,9 This leads to software with limited documentation and dependencies that are hard to maintain and reproduce. These challenges impede research progress. To ensure the sustainability of research software, there is a need for education in software engineering principles and practices, supported by established methods, tools, and technologies, to facilitate the long-term usability and evolution of software for future generations of scientists. SURESOFT is a twofold approach aimed at addressing challenges in the development of research software for sustainable science. This approach combines tools and infrastructure with educational components like workshops and training.10
Approaches from modern software development can be transferred to processes in research institutes to enable holistic RDM on an institute level. This contribution presents the Institute of Steel Construction’s implementation of holistic RDM, adapting the twofold approach form SURESOFT. The constraints and requirements of traditional scientific work processes are explained in the chapter Challenges. The implemented concept is presented as a use case using the process chain for the uniaxial tensile test on additively manufactured HSLA samples.
Use case: Uniaxial tension test of additive manufactured HSLA-steel
Core principles
The Institute of Steel Structures has adopted the SURESOFT approach to a holistic RDM on an institute level, encompassing all data regardless of research project guidelines. This entails reevaluating previous data collections and postprocessing. Three goals have been established: (1) implementing a consistent automated digital data flow based on an object-oriented process, (2) linking all data sources and metadata throughout the process chain, and (3) providing continuous training in documentation, software development and software testing. The approach is based on the requirements of the various shareholders, but also on the experience with modern research software development gained during the training sessions of the SURESOFT project.11 These basic principles from software development were transferred to the demands and existing workflows at the institute.

Fig. 1: Experimental setup with DIC measurement in a servo-hydraulic test rig (left), WAAM-HSLA-test specimen (right).12
Automated digital data flow and linking all data sources
In the following, the workflow of the holistic FDM at the institute level is shown using the example of a test setup from subproject A07 of TRR 277. The test setup shows how data from different sources are collected, merged, and evaluated on the basis of object-oriented processes. In wire and arc additive manufacturing (WAAM) of high-strength steel (HSLA), a lot of data is generated that potentially influences the component properties. As shown in Fig. 1, the components have a surface effect, which is referred to as as-built. To produce these components, a robot with a welding unit is required. Software generates a manufacturing strategy based on a CAD drawing (as-designed). This strategy contains path data and local welding parameters. During manufacturing, the surface temperature is also recorded in a localized manner. After manufacturing, the component is scanned at high resolution, resulting in a surface geometry. Subsequently, the component is subjected to a material test in a testing device, with force and displacement (or strain) being measured. In parallel, the displacement field is captured on both sides with a DIC system. The data is linked via various references: coordinate system, ICP matching, paths, time, or force signal.
Currently, the data processing chain is based on a technically low-level hardware and software, Fi. 2. The process is object-oriented, as described in a separate Matlab framework Materialtest. The core is the superclass MaterialTest, which describes essential properties and functionalities. From this, a specific test class MonotonicTest is created via inheritance and holds for the specific test setup and object of MonotonicTestProcedure form the superclass TestProcedur. The actual experiment series is then instantiated in each case. The framework controls the storage structure, data integration and testing for consistency. The storage itself is done on the cloud system nextcloud. The aim is that an export is possible via interface classes between the institute’s own RDM framework and the specification of the required RDM structure of external projects. The framework is based on the principles of modern software development, clean code and automated testing. The source code is stored in a git repository. We are currently working on an automated software test pipeline to enable continues integration. This has been partially implemented for analysis methods in the field of DIC measurements.
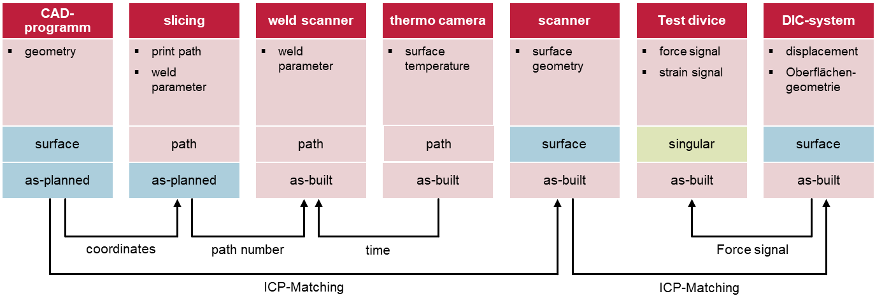
Fig. 2: Description of data processing in the presented application, data generated during a test series and their linking
Education and knowledge management
Qualification and training call for action at different levels. At the management level, room is created for both personal and institutional training. First and foremost, the management level needs a commitment to process orientation and change management. With reference to the use case, the management has to convince the staff that process thinking leads to efficient workflows and in the long term to better research quality. When it comes to implementing processes, interaction and communication between management, research, and technician staff is important. To create room for communication and exchange, the institutes has setup monthly meetings which are dedicated to exchange, documentation, and software/hardware maintenance. Staff and management must use the day for this purpose. Therefore, it is ensured that everybody can participate.
On the personal qualification level, individual training requirements arise as a result of process orientation. For research staff, it is common to have training in the field of principles of software engineering, clean code and refactoring, version control using git, and software testing. For technical staff, the qualification is more individual and takes into account the personal expertise level. Typical qualifications are principles of software engineering and programming, but also introduction to research data management to create workflow awareness. Qualification on a management level must be performed on research management and process organization.
Sseveral instruments have been implemented to ensure knowledge management over generations of researchers and technicians. To preserve the knowledge regarding experimental testing, the modular processes are described in a documentation. But personal exchange between experience and new staff is more important. This exchange is ensured by different formats. Workshops on special topics are organized between research and technical staff. In a bidirectional way, the research staff gives introductions on how to use new equipment or evaluation methods. The technical staff provide their many years of experience with the available test equipment and test methods.
Overall training and education play a key role to transform research work on institute level. But change is not possible without the commitment of the management level to process orientation and provide time and resources.
Discussion and conclusion
The example shows that research tasks can be solved by a common process-oriented description of research processes. Through the object-oriented description, different types of data can be collected, linked, and processed. The advantage is an automated workflow, modularization of evaluation routines, and reusability. Due to the mapping and uniform description on the institute level, it is possible to act independently of external requirements on RDM.
The challenge is that the already limited resources in research, especially in the implementation and training phase, are heavily used. Therefore, the goal must be for RDM to become a stronger focus of standardization on the institute level as well. Not every institute can or should set its own procedures here.
In summary, this contribution emphasizes the importance of RDM in scientific investigations. It discusses the fragmented nature of RDM implementation, particularly in structural engineering, and presents the Institute of Steel Construction’s approach to holistic RDM. The example of the uniaxial tensile test demonstrates the process chain and goals of automated data flow, data source linking, and continuous training.
Acknowledgements
The research presented in this paper is being conducted within the project “Wire Arc Additive Manufacturing (WAAM) of Complex and Refined Steel Components (A07).” The project is part of the collaborative research center “Additive Manufacturing in Construction – The Challenge of Large Scale,” funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) project number 414265976 – TRR 277.
References
- Wilkinson Mark D., Michel Dumontier, I. Jsbrand Jan Aalbersberg, Gabrielle Appleton, Myles Axton, Arie Baak, Niklas Blomberg, Jan-Willem Boiten, Luiz Bonino Da Silva Santos, Philip E. Bourne, Jildau Bouwman, Anthony J. Brookes, Tim Clark, Mercè Crosas, Ingrid Dillo, Olivier Dumon, Scott Edmunds, Chris T. Evelo, Richard Finkers, Alejandra Gonzalez-Beltran, Alasdair J. G. Gray, Paul Groth, Carole Goble, Jeffrey S. Grethe, Jaap Heringa, Peter A. C. ‘t Hoen, Rob Hooft, Tobias Kuhn, Ruben Kok, Joost Kok, Scott J. Lusher, Maryann E. Martone, Albert Mons, Abel L. Packer, Bengt Persson, Philippe Rocca-Serra, Marco Roos, Rene van Schaik, Susanna-Assunta Sansone, Erik Schultes, Thierry Sengstag, Ted Slater, George Strawn, Morris A. Swertz, Mark Thompson, Johan van der Lei, Erik van Mulligen, Jan Velterop, Andra Waagmeester, Peter Wittenburg, Katherine Wolstencroft, Jun Zhao and Barend Mons. 2016. “The FAIR Guiding Principles for scientific data management and stewardship”. Scientific data 3: 160018. doi: 10.1038/sdata.2016.18. ↩︎
- Redöhl Brit. 2016. The DFG Perspective: Research Data Management with a Focus on Collaborative Research Centres (SFB). Geographisches Institut der Universität zu Köln – Kölner Geographische Arbeiten. doi: 10.5880/TR32DB.KGA96.12. ↩︎
- Kapogiannis Georgios, and Fred Sherratt. 2018. “Impact of integrated collaborative technologies to form a collaborative culture in construction projects”. Built Environment Project and Asset Management 8: 24–38. doi: 10.1108/BEPAM-07-2017-0043. ↩︎
- Wang Wei, Tobias Göpfert, and Rainer Stark. 2016. “Data Management in Collaborative Interdisciplinary Research Projects—Conclusions from the Digitalization of Research in Sustainable Manufacturing”. ISPRS International Journal of Geo-Information 5: 41. doi: 10.3390/ijgi5040041. ↩︎
- Mozgova Iryna, Oliver Koepler, Angelina Kraft, Roland Lachmayer, and Sören Auer. 2020. Research Data Management System for a large Collaborative Project. doi: 10.35199/NORDDESIGN2020.48. ↩︎
- Altun Osman, Tatyana Sheveleva, André Castro, Pooya Oladazimi, Oliver Koepler, Iryna Mozgova, Roland Lachmayer, and Sören Auer. 2021. Integration eines digitalen Maschinenparks in ein Forschungsdatenmanagementsystem. doi: 10.35199/dfx2021.23. ↩︎
- Blech Christopher, Nils Dreyer, Matthias Friebel, Christoph Jacob, Mostafa Shamil Jassim, Leander Jehl, Rüdiger Kapitza, Manfred Krafczyk, Thomas Kürner, Sabine Christine Langer, Jan Linxweiler, Mohammad Mahhouk, Sven Marcus, Ines Messadi, Sören Peters, Jan-Marc Pilawa, Harikrishnan K. Sreekumar, Robert Strötgen, Katrin Stump, Arne Vogel, and Mario Wolter. 2022. “SURESOFT: Towards Sustainable Research Software”. doi: 10.24355/dbbs.084-202210121528-0. ↩︎
- Joppa Lucas N., Greg McInerny, Richard Harper, Lara Salido, Kenji Takeda, Kenton O’Hara, David Gavaghan, and Stephen Emmott. 2013. “Computational science. Troubling trends in scientific software use”. Science (New York, N.Y.) 340: 814–815. doi: 10.1126/science.1231535. ↩︎
- Merali Zeeya. 2010. “Computational science: …Error”. Nature: 775–777. ↩︎
- Blech; Dreyer. “SURESOFT: Towards Sustainable Research Software”. ↩︎
- Blech; Dreyer. “SURESOFT: Towards Sustainable Research Software”. ↩︎
- Jahns Hendrik, Julian Unglaub, Johanna Müller, Jonas Hensel, and Klaus Thiele. 2023. “Material Behavior of High-Strength Low-Alloy Steel (HSLA) WAAM Walls in Construction”. Metals 13: 589. doi: 10.3390/met13030589. ↩︎